Hint: The Cause and Fix Are Not What You Think
The classic line “I have a bad feeling about this” is repeated in every Star Wars movie. It’s become a meme for that uneasy feeling that as bad as things are now, they are about to get much worse. That’s an accurate portrayal of how many of us feel about cybersecurity. Our bad feeling has a sound empirical basis. Yearly cybersecurity losses and loss rates continually increase and never decrease despite annual US cybersecurity expenditures in the tens of billions of dollars and tens of millions of skilled cybersecurity man-hours. Cybersecurity’s record of continuously increasing failure should prompt thoughtful observers to ask questions like “Why are cybersecurity losses going up? Why isn’t cybersecurity technology reducing them? Are there things we don’t understand or are overlooking?”
That’s easy to answer: Of course, there are! After spending this much time, money, and brainpower on cybersecurity without managing to decrease losses, much less eliminating them, it’s painfully obvious something isn’t right.
This article explains what we get wrong about cybersecurity, how and why we get it wrong, and how to fix it. Fair warning: it’s a long and bumpy road. There a healthy dose of counterintuitive assertions, cybersecurity heresy, and toes stepped on, but at roads end you’ll know what the true cause of cybersecurity failure is and how to fix it.
Part One – Cybersecurity Technology
The Heart of the Matter
When confronted with a chronic problem, we human beings are prone to err by trying solutions without first asking the right questions. We tend to ask, “How do we stop this now?” and fail to ask, “What’s causing this?” Then we are shocked when our fixes don’t last. This tendency is so common that safety engineers developed a formal analytical method called a root cause analysis to prevent this error. Root cause analysis is designed to find unidentified causes of recurring failure. A root cause analysis starts with an effect, in this context, a failure, and works upstream all the way through the chain of causation until the root cause is found. In complex systems like computers, finding the root cause of failure is critically important because an unidentified root cause makes multiple downstream elements of the system much more prone to fail. You can tell when you’ve found the root cause, because if you fix it, the downstream recurring failures cease.
Identifying the root cause in complex systems can be hard because:
- A single root cause can spawn multiple instances and types of failure because a single root cause can spawn multiple chains of cause and effect. The chains can be long, having many intermediate cause and effect links between the root cause and the failure. The more links in the chain, the longer the “distance” between the root cause and the failure. Long chains branch and intersect with other chains, which makes it even more difficult to identify the root cause.
- Usually, the longer the distance is between an unidentified root cause and the failures it’s causing, the harder the root cause it is to identify. The shorter the distance between an intermediate cause and the failures, the easier the intermediate cause it is to identify. Intermediate causes are obvious, unidentified root causes are not—and that’s why root causes are so often overlooked.
Because of these difficulties, problem solvers can easily fall prey to the symptomatic solution fallacy, a mistaken belief that solving intermediate problems can permanently stop long distance failures. It’s called the “symptomatic” solution fallacy because it’s the engineering equivalent of a doctor believing that a treatment is curative when it only temporarily alleviates symptoms of an undiagnosed chronic disease. For example, a dose of pain medication can temporarily alleviate suffering, but it can’t cure the cancer that’s causing the pain.
To see how root cause analysis aids in finding and fixing unidentified root causes, we’ll review a common real world root cause analysis and then take the lessons learned and apply them to cybersecurity technology and then to cybersecurity policy.
Root Cause Analysis 101
The purpose of automaker safety recalls is to prevent recurrent failures attributable to a previously unidentified root cause. Recently, 700,000 Nissan Rogue SUVs were recalled because:
“In affected vehicles, if water and salt collect in the driver’s side foot well, it may wick up the dash side harness tape and enter the connector. If this occurs, the dash side harness connector may corrode and possibly cause issues such as driver’s power window or power seat inoperative, AWD warning light ON, battery discharge, and/or thermal damage to the connector. In rare cases, a fire could potentially occur, increasing the risk of injury.”
Lesson Learned 1. A root cause analysis, and ultimately the recall, was initiated by the automaker because it observed a pattern of multiple types of recurring failure that appear to be related, in this case multiple types of electrical failures.
Lesson Learned 2. From the perspective of the driver, if your power windows or seats stop working, or your car won’t start because the battery is dead or wiring in the dashboard of your 2014-2016 Nissan Rogue catches fire, it’s apparent that the problem is electrical. The root cause analysis revealed that the closest cause to these electrical failures was obvious, a corroded wiring harness connector.
Now, imagine the automaker had identified the wiring connector as the root cause and declared that replacing it was a permanent fix. It would soon be evident that the automaker had fallen prey to the symptomatic solution fallacy because replacing the connector would not be a permanent solution. The still unidentified and unfixed root cause would cause the replacement connector to corrode again, which, in turn, would cause one or more of the related failures to recur.
Key Point: After a fix has been applied, if related failures continue recurring, it’s evident that an intermediate cause was erroneously identified as the root cause.
Lesson Learned 3. Working the chain of causation backwards, the automaker deduced the cause of corrosion was exposure to moisture and a corrosive. What was the source? They deduced that the wiring harness tape wicked moisture and salt up to the connector, but where did the water and salt come from? They deduced the wiring harness was being wetted as it traversed the footwell.
The potential presence of water and salt in the footwell of an SUV is a known operating condition. A given vehicle may or may not encounter salt and water during its lifetime, but it is a known potential operating condition for all SUVs. The automaker neglected to take this known operating condition into account when selecting the routing and the physical characteristics of the tape used to wrap the wiring harness. Therefore, the root cause of failure is that the automaker neglected to compensate for a known operating condition in its design. Note that this finding is axiomatic; truly unforeseeable root causes are rare.
Key Point: In complex systems, it is axiomatic that recurring failures attributable to a previously unidentified root cause nearly always results from neglecting to compensate for known operating conditions in the design.
Lesson Learned 4. Now that the root cause has been identified, the automaker will conduct a requirements analysis to clarify operating conditions, needs, and goals of the fix, and then redesign to compensate for overlooked operating condition and minimize their and their customers’ risk and expense.
Lesson Learned 5. Since the automaker neglected to compensate for a known operating condition—potential exposure of an SUV to water and salt—in their design, the automaker is responsible legally, financially, and morally, for fixing the affected vehicles and making certain that the overlooked operating condition is compensated for in the design of all future models.
Summary of Root Cause Analysis Lessons Learned:
- Lesson Leaned 1: A pattern of multiple types of recurring related failures indicates the presence of an unidentified root cause.
- Lesson Learned 2: If repeated fixes fail to stop recurring failures, it indicates fixes are being applied to intermediate causes (symptoms), rather than to the root cause.
- Lesson Leaned 3: It is axiomatic that neglecting to compensate for a known operating condition in the design is nearly always the root cause.
- Lesson Leaned 4: To fix the root cause, a redesign compensating for the overlooked operating condition is required.
- Lesson Leaned 5: The designers neglected to compensate for a known operating condition, therefore, they are responsible for fixing existing and new designs.
What’s Wrong with Cybersecurity Technology?
Now we’ll apply the lessons learned above to cybersecurity:
Lesson Learned 1: A pattern of multiple types of recurring related failures indicates the presence of an unidentified root cause.
In cybersecurity, is there a pattern of multiple types of recurring failures that appear to be related? Yes! A cybersecurity failure occurs whenever a cyberattacker gains control of data and then: 1) views or plays it, 2) steals copies of it, 3) ransoms it, 4) impedes its flow, 5) corrupts it, or 6) destroys it. The lesson learned is that the target of cyberattacks isn’t networks, computers, or users; they are vectors (pathways) to the target—gaining control of data.
Lesson Learned 2: If repeated fixes fail to stop recurring failures, it indicates fixes are being applied to intermediate causes (symptoms), rather than to the root cause.
In cybersecurity, is there evidence of the symptomatic solution fallacy? In other words, is there a history of applying fixes to recurring related failures only to have the failures continue to occur? The answer is an emphatic yes. Successful cyberattacks keep on happening.
Groundhog Day
Why aren’t symptomatic solutions able to permanently solve cybersecurity failures? Because it’s mathematically impossible for them to do so. Don’t take my word for it; you can prove it to yourself with a simple thought experiment.
Compute “total cyberattack potential:”
- Identify vulnerabilities: Identify every type of user, hardware, software, and network vulnerability that can be exploited to gain control of data. To provide some scope, there are currently nearly 170,000 publicly disclosed cybersecurity vulnerabilities with new ones being discovered all the time.
- Count vulnerability instances: Add up the total number of users, networks and instances of software and hardware that have the vulnerabilities identified in step 1.
- For every vulnerability instance, identify and count every vector or combination of vectors a cyberattacker can take to exploit the vulnerability.
- Multiply vulnerabilities by their vectors to compute “total cyberattack potential.”
Now compute “total cyderdefense potential:”
- Identify every currently available type of defense, including technological defenses and human defenses such as cybersecurity training and education.
- Subtract unerected defenses due to apathy, ignorance, or a lack of trained personnel, money, or time.
- Subtract unerected defenses that don’t yet exist due to the lag time between discovering a vulnerability and developing a defense for it.
- Subtract unerected defenses arising from vulnerabilities known to cyberattackers but unknown to cyberdefenders.
- Subtract properly erected defenses that cyberattackers have learned to defeat.
- Subtract defenses that fail because they were improperly implemented.
It easy to see that there is far more total attack potential than defense potential, but we’re not nearly finished.
- Factor in that cyberwarfare is immensely asymmetrical. If a cyberdefender scores 1,000,000 and a cyberattacker scores 1, the cyberattacker wins.
- Factor in that the rate of asymmetry grows as the number of connected devices grows. Defense potential grows linearly since symptomatic point solutions are implemented individually, whereas, attack potential grows exponentially due to network effect. Think of an ever-expanding game of Whac-A-Mole where new holes and moles appear faster and faster, but kids with mallets only appear at a constant rate and you’ve got the picture. That tends to make cybersecurity successes temporary, as in unable to guarantee success against tomorrow’s attack even if successful today. For example: Someone at your company (or maybe you) buys a smart refrigerator. Later, via a new smart refrigerator exploit, the refrigerator’s software, which your company has no control over, is the initial vector that ultimately results in the theft of company intellectual property. The refrigerator, a single node added to an employee’s home network, negates the efficacy of all the company’s point solutions even if they all worked perfectly, not to mention diminishing the value of prior cybersecurity expenditures.
- Factor in that cybersecurity is truly democratic; the enemy gets a vote. Cyberattacker strategies, tactics, target valuations, and target selections are based on their cost-benefit analysis, not yours.
- Finally, factor in that defense is far more expensive than attack with respect to time, money, and trained personnel because it’s much easier to automate and distribute attacks than defenses. A relatively small number of cyberattackers can create work for a much larger number of cyberdefenders.
Accordingly, it’s not possible to calculate risk or a credible return on investment for implementing symptomatic point solutions. In its simplest formulation, risk = likelihood x consequences. It’s not possible to calculate the likelihood of being successfully cyberattacked because it’s not possible to know what exploitable vectors and vulnerabilities remain unprotected after implementing symptomatic point solutions.
In a successful cyberattack, the attacker has control of your data, so it’s impossible to predict the consequences. You can’t know with certainty what they are going to do with your data, nor can you know with certainty how much third parties like customers, courts, and regulators might penalize you for failing to keep cyberattackers from gaining control of your data. So, when a symptomatic point solution provider claims that buying their stuff will reduce your risk or provide a quantifiable return on investment, it’s meaningless marketing hype. That being said, at the present, symptomatic point solutions do provide a benefit by preventing some unknowable number of cyberattacks from succeeding. However, they are by their nature mitigative, not curative.
Key Point: Today’s multibillion-dollar cybersecurity industry is based on a symptomatic point solution fallacy.
Key Point: Organizations and individuals can’t implement a sufficient number and variety of symptomatic point solutions quickly enough to achieve anything approaching a permanent solution.
Key Point: The aggregate efficacy of symptomatic point solutions cannot be quantified or predicted, so return on investment cannot be calculated.
Key Point Symptomatic point solutions are of inherently limited efficacy, and while they are currently necessary, they can only be stopgap measures. As a result, cybersecurity success based on symptomatic point solutions is a crapshoot.
Lesson Leaned 3: It is axiomatic that neglecting to compensate for a known operating condition in the design is nearly always the root cause.
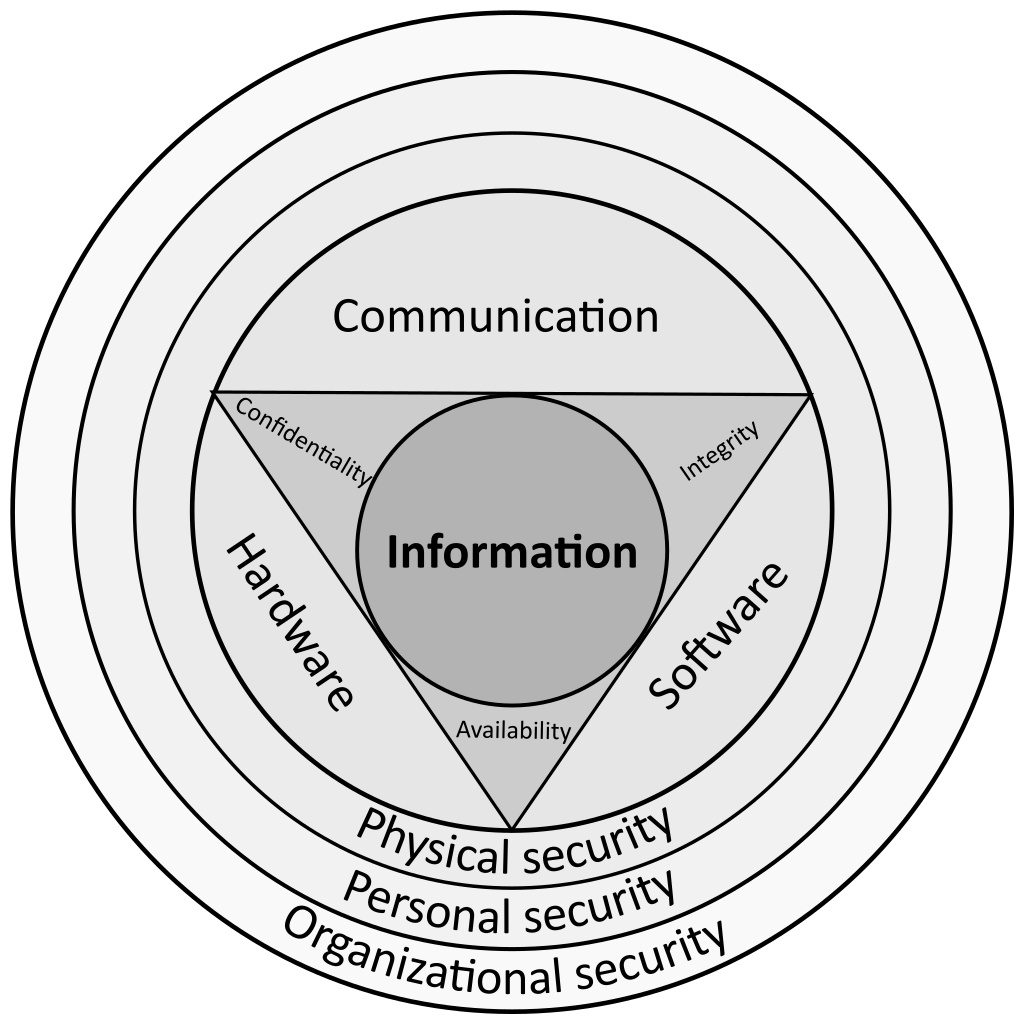
We know that cybersecurity failure is the result of a cyberattacker gaining control of data and doing things with it that its rightful owner didn’t intend. That makes it clear that there is something about data that permits cyberattackers to gain control of it, so deduction starts by asking “What are the relevant properties of data, and how is it controlled?”
Necessary Ingredients
Data in this context is digitized information. Digital information is physical, as in, it’s governed by the laws of physics. Data is the result of software converting (digitizing) human usable information into patterns of ones and zeros that are applied to “quantum small” physical substrates: microscopic transistors, electrical pulses, light, radio waves, magnetized particles, or pits on a CD/DVD.
The nomenclature can be a bit confusing. Files, streams, centralized databases, decentralized databases (blockchains), and software are all forms of digitized information. Software (or “applications”) is the generic name we give to digitized information that performs work on other kinds of digitized information. The digitized information that software performs work on, that is, it creates, processes, stores, and transports, is generically referred to simply as data. Software is accurately understood as a manufacturing process because it is a physical mechanism that creates data, uses existing data as a feedstock to produce new data, and manages data in storage and shipment.
It is important to note, especially when we get to cybersecurity policy in Part Two of this article, that human beings, contracts, laws, regulations, treaties, righteous indignation, and wishful thinking can’t directly control data—software, and only software, can do that.
Key Point: It’s impossible for human beings to directly control the creation, use, storage, and transport of data, only software can do that. Therefore, to be effective, policy must be enforced by software.
Once Upon a Time
When information was first digitized in the early 1950s, the community of people with computers was tiny, known to each other, and most had security clearances. Security was not an operating condition that software makers had to compensate for in their design. Consequently, data was designed with only two components: digitized information (the “payload”) and metadata (information about the payload)—a name and physical address, so software could retrieve existing data and work on it. This two-component data format is intentionally open, that is, it is inherently accessible. That’s a mouthful, so we’ll give the two-component data format a simple name: “open data.”
Fast forward to the Internet. Suddenly, n number of copies of open data can be made and transported anywhere by anyone at any time, processed by any compatible instance of software installed on any device, and every one of those copies is also inherently accessible because the data is open. Open data has no attributes that support constraining who, on what devices, when, for how long, where, or for what purposes it can be used, and no attributes that support tracking, managing, or revoking access once it has been shared. There are also no attributes in open data that support knowing who the data belongs to, what its purpose is, where it’s going, or where it’s been. The original instance and every single copy of open data in storage and in transport is inherently accessible and therefore, available for cyberattackers to control.
Not only can a cyberattacker in control of open data do whatever they want to with it, there is no way to see what they are doing with it or stopping them from doing it.
Key Point: The form of data is as software makes it to be.
Key Point: With exceedingly rare exception, software still produces open data by default—and therein lies the fundamental technology problem.
It’s no coincidence that the first recorded use of the word cybersecurity was in 1989, the year the commercial Internet was born.
Clear and Present Danger
Open data is inherently hazardous. A hazard is any physical thing or condition that has the potential to do harm. Harm can be physical, emotional, or financial. Data isn’t generally understood to be a physical hazard akin to a toxic chemical or a faulty bridge over a deep gorge because humans aren’t able to directly perceive data, manipulate it, or assess its condition. However, when quantifying how hazardous a thing is, the form and size of the thing or how it operates is irrelevant.
Key Point: The sole determiner of how hazardous a thing is the harm it causes when it’s not adequately controlled.
By the normal definitions of hazardous and harmful, can there be any doubt that open data is hazardous and when cyberattackers gain control of it, it’s harmful?
- Is open data under the control of cyberattackers doing hundreds of billions of dollars of financial harm every year? Yes.
- Is it causing human beings’ endless grief and misery? Yes.
- In an increasingly digitally controlled physical world, can open data inflict grievous bodily harm or death? Yes. In his book, “Click Here to Kill Everybody” world renowned cybersecurity expert Bruce Schneier summarizes potential physical harms this way:
“The risks of an Internet that affects the world in a direct physical manner are increasingly catastrophic. Today’s threats include the possibility of hackers remotely crashing airplanes, disabling cars, and tinkering with medical devices to murder people. We’re worried about being GPS-hacked to misdirect global shipping and about counts from electronic voting booths being manipulated to throw elections. With smart homes, attacks can mean property damage. With banks, they can mean economic chaos. With power plants, they can mean blackouts. With waste treatment plants, they can mean toxic spills. With cars, planes, and medical devices, they can mean death. With terrorists and nation-states, the security of entire economies and nations could be at stake.”
Key Point: Given its vast destructive potential, open data may be the most hazardous thing mankind has ever created.
Lesson Learned 3 states “It is axiomatic that neglecting to compensate for a known operating condition in the design is nearly always the root cause.” What missing known operating condition has been neglected? Continuous unrelenting cyberattack. Yet software makers continue to produce open data as if we were still living in the 50s, and the Internet had never been invented.
So, what is the root cause of cybersecurity failure?
Key Point: The root cause is software makers’ neglecting to incorporate a known operating condition, continuous unrelenting cyberattack, into to the design of data and the software that makes and manages it.
Key Point: The root cause is not cyberattackers; they are merely opportunists taking advantage of software makers’ neglect.
Lesson Learned 4: To fix the root cause, a redesign compensating for the overlooked operating condition is required.
Now that we have identified the root cause, we can formulate the top-level engineering requirements needed to fix the problem:
- Conditions
- Data is hazardous
- Cyberattack is continuous and unrelenting
- Harm is done when cyberattackers take control of data
- Needs
- Data owner’s shall be able to control their data
- From the moment it’s created until the moment it’s destroyed
- Whether it’s shared or unshared
- Whether it’s the original or a copy
- When it’s in storage, in transit, or in use
- Data owner’s shall be able to control their data
- Goals
- The solution shall be least cost and least time to implement
Safety Notice
Notice that even though the topic is cybersecurity, the conversation has shifted towards safety. Safety is the more appropriate way to frame the engineering and policymaking tasks at hand. Safety and security overlap, but security is reactive; it is oriented towards repelling attacks by erecting defenses. Safety is proactive; it is oriented towards preventing harm by containing and controlling hazards. Safety is the ounce of prevention; security is the pound of cure.
Put a Lid on It
Fortunately, we have at our disposal untold millions of man hours of safety engineering focused on safely extracting benefits from the use of hazardous things. For example, our homes and the highways we travel on are chock full of beneficial things that can easily kill us, such as high voltage electricity, flammable/explosive natural gas, and tanker trucks filled with flammable or toxic chemicals driving right next to us. These very rarely do us harm because the hazards are contained in storage and in transit, and their usage is controlled. Containment keeps hazardous things in until they are released for use. Controls enable hazardous things to be used safely.
Containers and controls enable the safe use of hazards things. If you are familiar with propane grills, think of the tank, tank valve, pressure regulator, and burner knobs. They are each engineered to safely extract a specific benefit—delicious grilled food—from highly hazardous propane. The tank is the container which safely contains propane in storage and in transport. The tank valve and pressure regulator are system controls. Even if the tank valve is opened, gas won’t flow, because a safety mechanism in the valve constrains the flow of gas unless a pressure regulator is properly attached. The pressure regulator constrains the flow of gas to a specified maximum volume and pressure. The burner knobs are user controls. They enable the user to instruct the grill to operate within a user-specified temperature range. So, a universal design principal for systems intended to extract a benefit from the use of a hazardous material can be formulated as follows: The hazardous material shall be safely contained until it’s put into use, the user shall be provided controls for extracting the specified benefit from use of the hazardous material, and system controls shall enable the user’s instructions to be carried out safely. How does this apply to the problem of open data?
Key Point: Data is physical and hazardous, therefore, the only way to use it safely is to contain it when it’s in storage and in transit and control it when it’s in use.
Data can be contained with strong encryption. If a cyberattacker gains control of strongly encrypted data but has no access to its keys, they can’t get it out of containment and do harmful things with it. When continuous unrelenting cyberattack is a known operating condition, there is no good reason to not encrypt all data by default the moment it is created, and from then on, only decrypt it temporarily for use. Only a tiny fraction of all data created is intended to be public. If you are its rightful owner, you can decrypt it and make it public whenever and wherever you choose. Can software encrypt data by default? Of course, it can. It’s known art.
Shot Caller
The first principle of controlling data is that control must be continuous. Data is distributed by making copies, and the copies can be processed by every compatible instance of software in existence. Therefore, the original and every copy must be accompanied by its user’s instructions. If those instructions don’t accompany the data, the recipient of the data, licit or illicit, can do whatever they want with it, and we are back to square one—open data.
The second principal of control is that each instance of data must have a unique, verifiable identity to support updateability and auditability. User instructions may need to be updated, such as changing access to data. The unique, verifiable identity supports traceability, usage logging, and proof of ownership, which means that the creation, distribution, and use of data can be fully auditable.
To accomplish this, software must make and manage a third data component. Open data has two components, the payload and metadata. The third component is instructions. When software takes the data out of containment, it consumes the data owner’s instructions and carries them out. When two-component data is shared, data owners are at the mercy of whomever is in control of the copy. When three component data is shared, each copy acts as a dynamic proxy for the data owner; it carries with it the data owner’s will and choices and can be updated and audited as needed. For brevity, we’ll call three-component data that is encrypted by default “controllable data.”
Controls provided by software enable data owners to instruct the system how their data can and cannot be used. To use data safely, the minimum controls are:
- Authentication Controls. Authentication determines who and what may temporarily decrypt data for use. A user must authenticate themselves to use their own devices safely, but when connecting their device to another device with which data will be shared, it is unsafe to authenticate the user only. Here’s why. To do work, computers require three physical actors working in unison:
- a user issuing instructions
- to an instance of software installed on
- an instance of hardware.
Cyberattackers only need to compromise one of these three actors to take control of data. Without consistently authenticating the user, instance of software, and instance of hardware requesting to connect, it is not possible to be certain who or what is on the other end of the line. Because each actor has unique physical characteristics, each combination of user, instance of software, and instance of hardware can be cryptographically authenticated. This process can be automated and made invisible to the user. It’s known art. We’ll refer to authenticating the user, instance of hardware, and instance of hardware as “full-scope authentication.”
- Temporal Controls. Most data isn’t intended to last forever, so data owners need to be able to control when and for how long their data can be used, and revoke access to shared data when recipients no longer need it.
- Geographical Controls. There are many use cases where data can only be used safely within specified physical or virtual locales. For example: physical location controls enable use only within a specified country. Virtual location controls enable use only within a specified organization’s network.
- Intended Use Controls. Usage controls constrain data to specified uses. For example, software can use data for purpose A, B, and C but not for purpose X, Y, or Z. Intended use controls can be customized for specific use cases, such as turning off a recipient’s ability to forward data to others or to export it from the controlling application. Intended use controls can be set directly by the user or they can be imported. When data is shared with a trusted third party, pre-agreed upon intended use controls can be imported from the third party and applied to the user’s data, and the software will objectively manage the use of the data for both parties.
It Wasn’t Me
Cyberattackers make a handy scapegoat. They provide endless revenue opportunities for symptomatic point solution providers and shifting responsibility away from software makers, but the fundamental mistake was ours; we allowed open data to metastasize throughout the connected world. For the reasons explained above, it is not possible to cure our open data cancer by treating its symptoms with a couple of aspirin, a few dabs of antibiotic cream, and some bandages.
Key Point: A hard truth about our current cybersecurity crisis is that we did this to ourselves.
Key Point: We got into this mess one piece of software and data at a time, so we’ll have to get out of it one piece of software and data at a time.
Agile Software Development, Known Art, and Updates to the Rescue
The “get out of it one piece of software and data at a time” requirement seems daunting, if not impossible, but it isn’t as bad as it sounds due to agile software development, the availability of “known art,” and the speed at which large-scale software changes propagate via the Internet.
A key attribute of agile software development is frequently releasing incremental improvements at short intervals, which is why we all experience a constant stream of software updates and patches. It is utterly routine for software makers to implement small to very large-scale changes to tens of millions of instances of their software overnight. To speed new capabilities to market, agile development relies heavily on prepackaged code developed by third parties, especially for functions that are common to all software, and that span across differing software architectures and programming languages. Creating, storing, transporting, and processing data are common to all software. The phrase “known art” above and below means there are multiple sources of prepackaged code that can enable the shift to controllable data to be quickly implemented in existing and new software. The key point is this:
Key Point: No new technology must be invented to shift software from creating open data to creating controllable data.
As a person whose first professional software development job in 1986 was to design and build accident analysis software for transportation safety experts, and who has been working with software developers ever since, I do not want to trivialize the amount of work required to shift the digital world from open data to controllable data and from partial authentication to full scope authentication. It will cost tens of billions of dollars and millions of man-hours of software development labor, and it will take years to fully accomplish. However, the cost of fully implementing controllable data and full scope authentication pales in comparison to the cost of continuing to produce open data and partially authenticate.
Left untreated, the total cost of cybersecurity failure (symptomatic point solution costs + cybersecurity losses) will continue to increase but shifting to controllable data and full scope authentication will sharply reduce both costs. To be sure, there will be initial and ongoing costs, but once initial implementation labor cost is paid, operating costs decrease and level out. Nonetheless, getting software makers to change their priorities to making their products safe rather than rolling out the next cool new feature will by no means be easy. However, when the diagnosis is fatal-if-left-untreated cancer, one should expect their priorities to change while treatment is underway.
Results of Implementation
Since this is a “big picture” article, the items in the list below are necessarily assertions without supporting technical detail. However, these results are not speculative, having been achieved in well-tested commercial software:
- Controllable data can only be decrypted by authenticated users
- Controllable data can only be used for the purposes its owner permits
- Stolen controllable data is unusable
- Remote cyberattackers can’t authenticate
- Malware can’t attach to software
- Stolen user credentials don’t grant access
- Stolen or cloned devices don’t yield usable data.
Ruining the Economics of Cyberattack
Would fully implementing controllable data and full scope authentication prevent every cybersecurity failure? Of course not. There are scenarios, particularly those aided by human gullibility, ineptitude, and negligence, where cybersecurity can and will continue to fail. However, cyberattacks are carried out by human beings for the purpose of acquiring money and/or exercising power, and there is a cost/benefit analysis behind every attack. Controllable data and full scope authentication, even though imperfect, increases the cost of illicitly gaining control of data by several orders of magnitude, thereby significantly diminishing the motivation to attack—and that’s the point.
Programming Ethics
The staff and management of many software makers are completely unaware of the inherent hazardousness of open data and partial authentication and their causal link to preventable cybersecurity harms. Many are genuinely committed to programming ethics, but their concept of cybersecurity is based on the symptomatic point solution fallacy. The fallacy is continually reenforced by their professors, peers, textbooks, trade publications, and endless articles about cybersecurity, most of which lead with images of a scary faceless hooded figure hunched over a keyboard—the dreaded cyberattacker. It would be unreasonable to hold them responsible for believing what they’ve been taught, especially given that symptomatic point solutions actually do thwart most cyberattacks; they’re just inherently insufficient due to the asymmetrical nature of attack and defense. That being said, once staff and management understand that cybersecurity failure is caused by software design, not cyberattackers, many professing adherence to programming ethics will have some hard decisions to make.
Part Two – Cybersecurity Policy
Lesson Learned 5. The designer neglected to compensate for a known operating condition, therefore, they are responsible for fixing existing and new designs.
When it comes to fixing a root cause, there are two questions. The first is “Who is able to apply the fix?”, and the second is “who is responsible for applying the fix?” The “who is able” question is about engineering because it’s about redesigning an engineered process. That was the subject of Part One—Cybersecurity Technology.
“Who is responsible” is about policy because the responsibility for preventing harm and assessing liability for failing to prevent harm is decided by policymakers, that is, by legislators and regulators. The role of policymakers is crucial if the strategy of software makers causing preventable harm is to evade their responsibility. That’s the subject of Part Two—Cybersecurity Policy.
The first question was answered earlier: Only software makers can apply the fix because data is the hazard, and the form of data is as software makes it to be. Logically, you would expect the answer to the “Who is responsible for applying the fix?“ to be “Obviously, software makers are responsible because 1) their product is causing preventable harm, and 2) they are the only ones able to fix it.” That entirely reasonable expectation would be buttressed by the fact that essentially every other kind of manufacturer of potentially harmful things, such as planes, trains, automobiles, chemical plants, pharmaceuticals, mining and pipeline equipment, children’s toys, and electrical appliances are all held responsible and liable for their design shortcomings when they cause preventable harm.
Unfortunately, perhaps tragically, policymakers aren’t holding software makers responsible for the preventable harms they are causing because policymakers too are caught up in the symptomatic point solution fallacy. In Part Two, we are going to focus on examining software maker motives, evasion tactics, and preventable harms resulting from the continued use of open data, and finish with policy recommendation and a look towards the future. Hold on tight—this long and bumpy road is about to get a lot rougher.
Close Encounters of the Third Kind
We have been taught to think of cyberattackers as being one of two kinds, criminal cyberattackers who gain control of others’ data to make money, or military/terroristic cyberattackers who gain control of others’ data to project military or political power. There is a third kind: Software makers who systematically destroy privacy, so they can gain control of as much “human data” as they possibly can.
Human data in this context is defined as the totality of all data about a specific person that can be gleaned from digital sources. This third kind of cyberattacker collects as much human data as possible because it is the “raw material” on which their business, in whole or large part, is based. We’ll call this third kind of cyberattacker “human data collectors” or HDCs for short.
HDCs include the world’s largest software makers—Google, Facebook, Microsoft, Amazon, and Apple—so-called “big tech”—followed by an enormous number of smaller players and a vast supporting ecosystem. HDCs are categorized as “cyberattackers of the third kind” because they are technologically, methodologically, motivationally, and morally identical to criminal and military/terroristic cyberattackers.
- Technologically, all three kinds of cyberattacker succeed by gaining control of others’ data.
- Methodologically, all three kinds of cyberattacker lie, inveigle, and deceive to gain control of others’ data.
- Motivationally, all three kinds of cyberattacker gain control of others’ data to make money, project power, or both.
- Morally, all three kinds of cyberattacker are indifferent to the harms they know they are causing.
Key Point: The technological goals, methods, motivations, and morals of all three kinds of cyberattacker are known operating conditions that policymakers must compensate for in the design of their policies.
Lie, Inveigle, Deceive
At any given moment, HDCs around the globe, especially “big tech” HDCs, are embroiled in hundreds of lawsuits brought by individuals and governments. They are accused of bad conduct that includes an astounding array of privacy violations, deceptive and unfair trade practices, price-fixing, anticompetitive behavior, violation of antitrust statutes, censorship, breach of contract, human resources violations, defamation of character, collusion, conspiracy, copyright infringement, patent infringement, and intellectual property theft. Collectively, HDCs have paid out billions of dollars in fines, penalties, settlements, judgments, and punitive damages. You would be hard pressed to find anyone knowledgeable of HDCs’ practices, other than their attorneys and publicists, who would assert they are of high integrity and are trustworthy.
The primary difference is that criminal and military/terroristic cyberattackers are outlaws, whereas HDCs operate as if they are above the law. HDCs will strenuously object to being characterized as cyberattackers, but if it looks like a duck, walks like duck, quacks like a duck, and swims like a duck . . .
It’s All About the Benjamins
Why are HDCs so willing to abuse their own users? For the money and the power that comes from having lots of it. In 2002, Google discovered that the raw human data it was collecting from its users to increase the quality of the user experience could be repurposed to deliver targeted ads, that is, ads delivered to an individual’s screen in real time based on what the individual was currently searching for, and those ads could be repeated, called ad retargeting. That capability turned out to be astoundingly lucrative. As of February 2021, Google’s market capitalization was approximately 1.4 trillion US dollars, and about 85% of their revenue comes from advertising. About 95% of Facebook’s revenue comes from selling ads.
That’s No Moon
Knowledge really is power, and HDCs act as gatekeepers to the sum of all digitized surface web content plus the sum of all the digitized human data they have collected to date. That’s a concentration of power never before seen in human history. Let’s take a closer look at current preventable harms enabled by that concentration.
Spilt Milk
HDCs are creatures of open data; they could not have come into existence, or continue to exist in their current form, without it. Their internal use of open data and dependence on symptomatic point solutions have resulted in multiple preventable harmful breaches of user personal information, and it is unreasonable to project that such breaches have come to an end. Future preventable breach harms are expected.
Free Spirit
In the list of cybersecurity failure types described previously, impeding the flow of data, is not well understood. Usually, it’s defined only as disrupting the flow of data such as happens in a denial-of-service attack. Another more insidious, and arguably more harmful, impedance is distorting the flow of information.
The ideal of the early Internet was to be the world’s public library, one that would provide near instantaneous and unrestrained access to the sum of all information available on the surface web (with one notable universal exception—child pornography).
Nobody expected that the information on the new-fangled world wide web would be completely accurate, truthful, and non-contradictory. Why? Because truth, lies, mistakes, misinformation, disinformation, bias, liable, slander, gossip, and the means to broadcast it to enormous audiences existed (gasp) before the Internet. A vital characteristic of a free society, pre-Internet and now, is that people 1) have the right to unimpeded access to public information, 2) are responsible for their own due diligence, and 3) are free to arrive at their own conclusions. Distorting the flow of public information diminishes each, and harms individuals and society as a whole.
Nudge, Nudge, Wink, Wink
Ads are a mix of useful to useless and entertaining to irritating, but nonetheless, producers have a legitimate need to market to their prospects. Advertising and persuasive marketing copy is neither illegal nor immoral. Targeting and retargeting ads based on real-time human behavior provided advertisers with a genuinely new capability, explained below by Shoshana Zuboff in “The Age of Surveillance Capitalism” (reviewed by Expensivity here):
“Advertising had always been a guessing game: art, relationships, conventional wisdom, standard practice, but never “science.” The idea of being able to deliver a particular message to a particular person at just the moment when it might have a high probability of actually influencing his or her behavior was, and had always been, the holy grail of advertising.”
However, Google and other HDCs didn’t stop there—and therein lies the fundamental policy problem.
Google, followed shortly by Facebook and others, discovered that, for a given individual, the greater the volume and diversity of raw human data they can collect and the longer they can collect it, the more effectively the data can be used to slowly and surreptitiously use algorithmic nudging to change the user’s beliefs and behaviors. In other words, HDCs treat human beings as perpetual guinea pigs in an endless and thoroughly unethical experiment by using software designed to learn how to manipulate their user most effectively. This is unethical because the intent of the HDC’s is to use its software to diminish personal autonomy, and they hide their intentions from their user for the most obvious of reasons: If the user becomes aware of how they are being manipulated and for what purposes, they’d likely be angered and demand that the manipulations stop.
In addition to nudging, since users see more ads the longer the stay logged on, HDCs began using their newfound user manipulation capability to addict users to their software. Details about the mechanisms of addiction are not within the scope of this article, but most rely on presenting information and controlling its flow in a manner designed to generate and reenforce a dopamine hit or to amplify negative emotions such as fear, anger, envy, guilt, revenge, and lust. HDCs’ algorithmic nudging and intentional addiction are increasingly understood to be harmful to individuals and society at large, as attested by numerous studies and whistleblower testimony. HDCs are keenly aware of the harm, but it hasn’t stopped them.
Key Point: Advertising isn’t the problem; user manipulation via surreptitious algorithmic nudging and intentionally addicting users is.
Key Point: The ability to manipulate users for one purpose creates the ability to manipulate users for any purpose.
Off Target
The promise and purpose of search technology is that with it a user can find what they are looking for, not what the search engine provider deems worthy of being found. That creates an inherent conflict of interest when search providers such as Google are able to increase their ad revenues by distorting the search results delivered to users. Distortion, in this context, is defined as arbitrarily differentiating search results between users, changing their order, and/or withholding results for the purpose of changing user’s beliefs or behavior. The distortion of search results, whether under the guise of “helping users to make good decisions” or selling advertising is still distortion. The quid pro quo of distorted search is: “You give us all of your human data, and we’ll use it to decide what we think is best for you to know.” Such distortion is enabled by enormously complex search algorithms that are claimed as trade secrets. The use of complex algorithms is not the problem, holding them secret is.
Key Point: When search results are distorted and search algorithms are held secret, the user cannot know how search results are being used to manipulate them.
A Day at the Races
Another manifestation of coupling advertising rates to user manipulation is Search Engine Optimization (SEO). In horse racing, a “tout” is a person who charges bettors for inside information about upcoming races. Touts are good for racetrack owners because people who pay for their knowledge are likely to bet more often and in larger amounts, especially if the tout really does facilitate the occasional win.
That’s a pretty good description of the Search Engine Optimization (SEO) business—they are touts for Google’s and other search provider’s racetrack. In 2020, SEO cost business about $39 Billion USD and millions of man-hours to produce SEO content. The problem with SEO is not that it is ineffective, rather that requirement to do SEO just to increase the odds of being found smacks of restraint of trade. The SEO tout/racetrack game is exclusionary. Many businesses, especially the approximately five million US small businesses with less than twenty employees, may not have the skill or money to engage in SEO; it’s not cheap. But without paying the touts, they cannot be assured of being found.
Stage IV Cancer
Thanks largely to Google’s and Facebook’s success, the collection of raw human data for purposes of monetization has metastasized throughout a significant portion of the software-making world. Some HDCs collect raw human data for their own use, but most collect it for resale. There are millions of HDC apps in the various app stores that are surveillance platform first and app second. These smaller HDC software makers sell human data to data brokers, who altogether do about $200 billion a year in human data trafficking. In the last few years, HDC software makers have been joined by some of the world’s largest hard goods manufacturers whose products happen to contain software that connects to the internet. Examples include automakers, television and other home entertainment device makers, home appliance makers, computer, mobile phone, and tablet makers, mobile device providers, toymakers, and Internet service providers, all anxious to cash in on raw human data.
Despite all this, in a fine example of Orwellian doublespeak, HDCs publicly proclaim themselves to be the champions and protectors of privacy while simultaneously hoovering up as much raw human data as they possibly can. They have redefined privacy from “I, as an individual, decide what, when, and with whom I’ll share information” to “We, as a company, will collect every scrap of your raw human data we can, declare it to be company property, do with it what we will, share it with whom we want, guard it from our competitors—and call the whole thing privacy.” When HDCs say, “We take extraordinary measures to protect your privacy!”, what they mean is “We take extraordinary measures to protect our property!”
Unnecessary Roughness
Many believe that mass raw human data collection is inevitable because advertising-supported HDCs must have it to provide their services for free. The HDC value equation has been “For users to benefit from our service for free, we must collect identifiable human information to fund our operation by selling targeted ads.”
That’s no longer true.
Privacy-enhancing technologies (PETs) that didn’t exist a few years ago are able to extract user attribute data needed to target ads from raw human data without extracting identity information. Software can make such attribute-only data controllable, so we’ll refer to it as controllable attribute-only data. Modern PETs used advances in math to assure that attribute-only data cannot be analyzed to identify specific individuals, and additionally, such analysis can be reliably prevented because the data is controllable. Modern PETs should not be confused with older data anonymization technologies that suffered from recurrent data re-identification problems.
The advent of controllable attribute-only data has a profound implication that policymakers should factor into their thinking. As before, since this is a big picture article, technical detail isn’t provided for the following assertion, but, like other technologies described above, it’s achievable with existing technology:
Key Point: HDCs can be monetized by targeted advertising without collecting raw human information.
Additionally, there are search engines that:
- Record zero information about the searcher
- Do not distort search results
- Enable users to make their own customizable persistent search filters. In other words, the user controls the search algorithm, not the search engine provider.
The technology to offer privacy-preserving, undistorted, user-controllable search supported by privacy-preserving targeted advertising exists. There is nothing to prevent existing advertising-supported search engines such as Google from “reforming” and ditto for advertising-supported social media. The point is that advertising supported HDCs can reform, but whether they will reform remains to be seen.
These Are Not the Droids You’re Looking For
Before suggesting specific policy fixes, it’s important to understand exactly what policy needs to fix. HDCs have been able to evade responsibility for the preventable harms they cause by 1) blame shifting and 2) arbitrarily transferring risk to their users.
HDCs blame cyberattackers for problems they themselves cause and only they can cure. They transfer what should be their own risk to their users by presenting them a Hobson’s choice embodied in license agreements. These agreements are filled with legalese so dense that the attorneys who don’t specialize in writing them have a hard time figuring out what they mean; the general public doesn’t have a chance. So, as a public service, I’ve translated and summarized them here:
- “You must click Accept, otherwise you can’t use our software. If you click Accept, you acknowledge that you can never ever hold us responsible for anything, and that the raw human data we take from you is our property, not yours, so we can do whatever we want to with it.”
When a user (or their attorney, or state attorney general, or federal official) complains, HDCs point to the user’s acceptance of the license and declare they aren’t responsible, no matter how egregious the harm.
Brave Old World
HDCs’ licensing strategy is designed to free them from any vestige of fiduciary duty. Fiduciary law traces its roots back to the Code of Hammurabi in 1790 BC, through the Roman Empire, early British law, and up to the present day.
The purpose of fiduciary law is to compensate for two sad facts of human nature. In unequally powered business relationships, 1) businesses with more power tend to abuse customers with less power, and 2) the greater the disparity of power between the business and the customer, the more likely customer abuse will occur if left unchecked. The purpose of fiduciary law is to inhibit customer abuse by assigning the business statutory duties to act in the best interests of their customers. There are many unequal power relationships between many kinds of businesses and customers, so there is an enormous amount of common and black letter fiduciary law for policymakers to draw on. Common fiduciary duties include:
- Duty of Care. Businesses have a duty to not harm their customers
- Duty of Loyalty. Businesses have a duty to not place their interests above the interests of their customers.
- Duty of Good Faith. Businesses have a duty to act in good faith, meaning they must deal fairly with customers. Examples of acting in bad faith towards customers includes lying to them, using deceptive practices, and shirking their obligations.
- Duty of Confidentiality. Businesses have a duty to protect their customers’ sensitive or confidential information.
- Duty of Disclosure. Businesses have a duty to act with candor, that is, to answer customers’ and regulators’ questions honestly.
A Slap on the Wrist
The high number of government-brought lawsuits against HDCs all around the world, the thousands of pages of laws and regulations designed to reign in HDCs’ bad behavior, the employment of thousands of regulators, and fines, penalties, judgments, and settlements in the billions of dollars make it abundantly clear that policymakers are aware of the harms HDCs are causing.
However, it is also abundantly clear that policymakers have fallen prey to the symptomatic point solution fallacy in two ways. First, to date, legislation, regulation, and litigation designed to reduce cybersecurity failure has been deterrence based, that is, if you don’t adhere to behavior A, you’ll get punishment B. Just like technological symptomatic point solutions, deterrence policy is an attempt to stop bad behavior (symptoms) instead of eliminating deficiencies in policy that enable HDC bad behavior (fixing the root cause).
Deterrence-based policy, like its technological symptomatic point solution cousin, is afflicted with a math problem. Deterrence implemented as criminal prosecution or political or military reprisal for successful cyberattacks cannot achieve a high enough ratio of successful prosecutions or reprisals to successful attacks to generate any real fear on the part of the cyberattackers. What miniscule success deterrence policy has achieved is perceived by criminal and military/terroristic cyberattackers as acceptable risk.
The same applies to deterrence measures contained within privacy laws and regulations. The ratio of punishments to revenues generated while violating laws and regulations is so low that big tech HDCs absorb them as merely the cost of doing business. Millions to billions of dollars in annual monetary penalties might sting them a bit, but when the aggregate cost of non-compliance is a small percentage of annual revenue which can be offset by charging captive advertisers slightly higher ad rates, they don’t do much of anything. The tens of thousands of small HDCs clogging up app stores tend to be domiciled overseas and too small to be worth prosecuting.
That’s why deterrence has hardly been more than a speed bump to cyberattackers, including big tech HDCs’ drive to acquire all human data and continuing to use it in harmful ways.
Key Point: if the metric for deterrence policy success is the degree to which it has decreased successful cyberattacks, including breaches, human data collection, lying, inveiglement, deception, and user manipulation, it’s had little success.
Key Point: The root cause of ineffective policy isn’t insufficient deterrence; it’s allowing software makers to arbitrarily exempt themselves from fiduciary duty and transfer their risk to their users.
A Poke in the Eye
Furthermore, in the domain of unintended consequences, deterrence polices are based on the technological symptomatic point solution fallacy. Businesses are assumed to be negligent if they have a data breach. That’s correct in some cases, but in others, businesses, particularly small and medium-sized businesses, suffer increased compliance costs or have been bankrupted by data breaches that they had no ability to prevent. Basing deterrence policy and penalizing businesses on the mistaken belief that symptomatic point solutions can reliably prevent data breaches makes about as much sense as fining the pedestrian injured in a hit and run because they failed to jump out of the way.
It is wrong to punish businesses for harms caused by software makers that the business using the software has no way to prevent. Punishing a business for data breaches provably caused by their own negligence is appropriate; punishing them for software makers’ negligence is not. Policymakers should distinguish between the two to prevent punishing the victim.
Possession is Nine-Tenths of the Law
The term “raw material” as applied to human data in this article is meant literally. Human data is “raw” at the point of collection. Raw human data has intrinsic economic value, but after it’s further processed by DHCs, its refined value is much higher. Think of an individual’s raw human data as you would crude oil, gold ore, or pine trees. Each has intrinsic economic value; they can’t be taken from a landowner by oil, mining, or lumber companies without the agreement of the landowner. Raw human data is material because as explained earlier, data is as physical as a brick—it’s just quantum small.
Wikipedia says that the saying “possession is nine-tenths of the law” means “ownership is easier to maintain if one has possession of something, or difficult to enforce if one does not.” The legal concept of ownership is predicated on an individual’s practical ability to control a physical thing’s use. Control enables possession, and possession codified in law confers legal ownership.
In law, possession can be actual or constructive. Actual possession means the thing is under your sole control. Constructive possession means a third party is permitted to use the thing, but your legal ownership is maintained, and usage is controlled by means of a contract. A simple example is a home that you own as your primary residence (actual possession) and a house that you own but lease to others (constructive possession). Constructive possession is especially relevant to data because data is usually shared by making a copy and transmitting it, not sending the original. Since a data owner would likely retain the original, it’s more appropriate to see shared data as having been leased, not sold.
Key Point: Controllable data enables constructive possession of data when it’s leased it to others, and it enables software to objectively enforce both sides of the lease.
Key Point: If users legally own the raw human data that their own digital activities create, it’s reasonable for policymakers to assert that fiduciary duties apply to those who collect it; they are being entrusted with an asset they don’t own.
The Easy Button
The most common objection to data ownership is that self-management of owned data is overly complex. That view is based on the complexity of so-called “privacy controls” offered by big tech HDCs, controls which have every appearance of being deliberately obtuse. As a software developer and designer, an industrial safety controls designer, and an IT system administrator, I am acutely aware that privacy controls could be greatly simplified, but they aren’t. Instead, they are hard to find, frequently change locations, get renamed, are vaguely defined, and provide no feedback to verify they are working. That’s either evidence of astonishingly poor design or an intent to convince users that managing their privacy just isn’t worth it. I’m going with the latter.
In fiduciary relationships, the burden of control complexity falls on the fiduciary, not the customer. It is the fiduciary’s duty to reduce complexity because it decreases the chances the customer can harm themselves when using the fiduciary’s product or service. If you open a bank or investment account, there is no expectation that you, the customer, are responsible for logging in to the fiduciary’s software as a system administrator and doing all the complex configurations required for your account, is there? Of course, not.
As stated earlier with respect to controllable data, “When data is shared with a trusted third party, pre-agreed intended use controls can be imported from the third party and applied to the user’s data.” That technological capability, in conjunction with fiduciary duty, puts the onus of managing complex controls on the fiduciary, not the customer. It’s part of the fiduciary’s duty to disclose in plain language how shared data entrusted to them will be used. That’s readily accomplished with an online portal with a simple user interface that, if appropriate, enables usage to be modified or revoked in accordance with contract terms—the same capability we have now with our banking and investment accounts. From a design standpoint, there is no reason for owned data shared with a fiduciary to be difficult to control.
Clear As Glass
In fiduciary relationships, the ability to inspect what the fiduciary is doing with the assets they are entrusted with is the norm. It has been asserted by some HDCs that such an inspection of a user’s data isn’t possible ‘because the data isn’t organized that way.’ That’s not credible.
When HDCs collect raw human data for their own purposes, say for targeting ads, it has knowledge of the user that is so granular that it can place ads selected for the specific user, count their ad clicks and views, monitor their movement about the page to gauge attention, store that information and recall it for future trend analysis, and invoice the advertiser for each ad seen or clicked. Given that level of capability and the amount of stored detail held for each individual user, HDC assertions they don’t have the technical wherewithal to disclose the sources, holdings, and uses of information related to a specific user is ludicrous. Likewise, those HDCs who collect human data for resale must have detailed information about the nature of the data they have collected and who they collected it from in order to value it and invoice the buyer. It’s not credible to assert they can’t disclose the sources, content of the information collected, and who they sold it to.
The problem isn’t that HDCs can’t produce and disclose the data source, content, and usage information for each user, it’s that they desperately don’t want to. Why? Because if their users see the volume and detail of the information HDCs hold on them and how they are using it, they would likely be stunned, horrified, and angry—and demand that it stops.
There’s A New Sheriff in Town
Given what we’ve covered, to reach the goals that deterrence-based policy has not achieved, policymakers should consider the following:
- Apply fiduciary law to software makers, otherwise they will continue to have no compelling reason to think about, much less do anything about the harms their software is causing.
- Declare that raw human data is the property of the individual whose digital activities generate it, not the property of the HDCs that collect it. Controllable data makes this more than a legal fiction because it makes actual and constructive possession of personal data possible, provable, auditable, and when shared under contract, objectively enforceable.
- With respect to human data collection:
- If the purpose of software can be fulfilled by consuming controllable attribute-only data, the collection of identifiable human data should not be permitted.
- If the purpose of software can only be fulfilled by the collection of identifiable human data, that data must be jointly controllable by the person that produced it and the receiving entity in a manner satisfactory to both.
- With respect to disclosure:
- Require that organizations holding identifiable human data disclose to each user the sources of their data, the content currently held, and how their data is used. A well-organized online portal would suffice.
- To prevent user manipulation, require that organizations holding identifiable human data
- Provide users a plain language explanation of any algorithmic processing of their data.
- Allow regulators to inspect the algorithms that consume that data and the data derived from it.
- With respect to data deletion:
- HDCs who no longer have a legitimate purpose for holding identifiable human data should make a copy in an organized format available to users upon request.
- If an HDC no longer has a legitimate purpose for holding a user’s identifiable human data, users should be granted the right to order its permanent deletion.
Preview of Coming Attractions
If policymakers start to move towards implementing the policies suggested above, there will be a pushback from software makers that are not HDCs. They will be unhappy about additional software development costs, and they will play the “It’s the cyberattackers, not us!” card, saying it’s unfair to hold them responsible for “unforeseeable” cybersecurity failures. Part One of this article was written to refute that argument.
Non-HDC software makers who license to organizations will have to negotiate defraying software development costs with their customers (the organization potentially harmed by their product), and most likely, both parties will involve their insurers—and that’s a very good thing. Insurers make their money by turning unquantifiable and unpredictable risk into quantifiable and predictable risk, and when it comes to hazardous manufacturing processes and products and compliance with laws and regulations, they do so by requiring insureds to implement technologies and techniques that are demonstrably effective. Software makers are likely to quickly change their software development priorities if they must do so to retain or obtain insurance coverage. When it comes to cybersecurity risk, working out rational risk sharing and engineering best practices between software makers, their customers, and their respective insurers is long, long, overdue.
Wall Street, J. Edgar Hoover, Langley, and Fort Meade
The pushback from HDCs, especially big tech HDCs, will be swift, brutal, loud, extremely well-funded, will include hordes of lawyers and lobbyists, but also some players you may not expect—Wall Street, and certain elements of the intelligence and law enforcement communities.
Why would Wall Street get in involved? The market capitalization of HDCs that depend primarily on the unfettered collection of raw human data to generate advertising revenue (Google, Facebook, and others with similar business models), isn’t predicated on their technology, intellectual property, or their physical plant, it’s predicated on the value of the human data they hold and their unimpeded ability to continue collecting it. The value of their human data holdings will plummet unless it is continuously “topped up” with raw human information. Why?
Users are dynamic. They are exposed to new information that impacts their current beliefs and behaviors, and it is precisely that malleable nature of human beings that algorithmic nudging exploits. If nudging algorithms are starved of new information, they cease to function in real time. The long experiment ends, and the guinea pig reverts to being an unmanipulated human being. The efficacy of manipulative advertising declines and it takes ad rates with it. Remember that prior to discovering that users could be algorithmically nudged and addicted, ad targeting was based on a relatively simple analysis of what users were currently searching for. Without continuous topping up, HDCs will have to revert to that model, and the historical data they hold would quickly lose value. Furthermore, if policy changes make HDCs liable for breaches of all that obsolete personal data they hold, the data would become a liability, not an asset. Why continue holding it?
The extreme sensitivity of HDCs to the loss of continued real-time raw human data collection was recently demonstrated by Facebook’s valuation losses after Apple gave users a choice to not be tracked by Facebook among others. Facebook lost 250 billion dollars of market cap. Wall Street is not favorably disposed towards those kind of shocks, so some are likely to pushback using familiar arguments along the lines of “They must be protected! They are too big to fail!”
Going Dark
When it comes to cybersecurity, law enforcement and the intelligence community are divided into two camps: those responsible for keeping data safe, and those who want unfettered access to data to protect individuals and the country. The latter group will lobby hard against the root cause fix described in Part One because it requires ubiquitous strong encryption to protect data in storage and in transit. The conflict that has been going on for decades is referred to as the “crypto wars.”
Based on past experience, the intelligence and law enforcement officials who disfavor ubiquitous strong cryptography will inevitably accuse pro encryption folks, including policymakers pushing for policies listed above, of aiding child pornographers, drug cartels, human traffickers, and terrorists. Pro-encryption policymakers should expect to be smeared. The anti-encryption narrative will focus on a special class of victims, not all victims.
The rhetorical trick anti-encryptors will deploy is to ascribe good and evil to a thing: encryption. They’ll say “Encryption is bad because bad people use it, and good people have nothing to hide, so they shouldn’t be able to use it.” To see how the trick works, let’s extend that logic to things we are more familiar with (1-2), then to encryption (3), and then show it “naked” (4):
- Child pornographers, drug cartels, human traffickers, and terrorists use planes, trains, and automobiles for evil purposes, so good people shouldn’t be able to fly, ride, or drive.
- Seat belts and airbags save many lives in traffic accidents, but in a few cases, they cause death, so cars shouldn’t have seat belts and airbags.
- Bad people use encryption to do bad things, so good people shouldn’t be able to use encryption to do good things.
- We can keep some people safe sometimes by keeping everyone unsafe all the time.
When anti-encryptors are called on the illogic of their rhetoric, they switch to “Encryption can be good if cryptographers can give us “exceptional access,” a magical method to void encryption on whatever they want whenever they want. Even if that were possible (it’s not, which is why it’s a magical method), you have to ask: is it a smart strategy to have a world-scale encryption voiding mechanism that perhaps can be stolen or figured out and replicated by your enemies? Probably not.
Finally, there are all sorts of encryption products and services sold all over the world available to everyone, good or bad, and encryption itself is applied mathematics that anyone with the right skills and desire can learn and use. Cyberattackers are already good at encryption—see ransomware. It’s impossible to prohibit bad guys from using encryption. So, how does prohibiting good guys from using it help?
End of the Road
There is a saying — “Once you know something is possible, the rest is just engineering.” That is applicable to the problem of cybersecurity. A certain resignation has set in, a belief that we just have to learn to live with ongoing and escalating cybersecurity failure and the loss of digital privacy. That’s not true. We know what the true cause of cybersecurity’s technological and policy failures are and that it is possible to start fixing them now. What remains to be seen is whether we, as a society, have the will to fix them and when we’ll get started.
About the Author
David A. Kruger has worked in software development, safety engineering, and risk analysis for over 35 years, with a focus on cybersecurity and digital privacy since 2009. He is a co-inventor of software-defined distributed key cryptography, a certified GDPR practitioner, and a member of the Forbes Technology Council.